
I am an incoming postdoc at the University of Washington, advised by Prof. Tim Althoff. I completed my PhD at the University of Chinese Academy of Sciences, where I am advised by Prof. Xueqi Cheng and Assoc. Prof. Bingbing Xu.
My research goal is to build Trustworthy AI that performs reliably and ethically for social good and human well-being. To achieve this, I worked on generalization, alignment and agentic system across the domains of graph, vision, and language. My research includes:
-
Machine Learning Generalization: To make models generalize stably under domain shifts, noises, or perturbations.
-
Large Language Model Alignment: To align large language models with human values and safety requirements.
-
Agent System Reasoning and Planning: To enhance agent’s logical reasoning and strategic planning for complex tasks.
🔥 News
- 2026.02: 🎓 I graduated from the University of Chinese Academy of Sciences (UCAS) and will join the University of Washington (UW) as a postdoctoral scholar!
- 2026.01: 🎉🎉 Our paper Incentivizing Strong Reasoning from Weak Supervision is accepted in EACL 2026 Oral.
- 2025.09: 🎉🎉 Our paper Inference-time Alignment in Continuous Space is accepted in NeurIPS 2025.
- 2025.09: 🥳 I am thrilled to join the NICE Committee!
- 2025.07: 🥳 We’re excited to host “The 1st Workshop on LLM Agents for Social Simulation” at CIKM 2025 in Seoul, Korea!
- 2025.06: 🎖 I received the President Award of the Chinese Academy of Sciences (CAS), the highest honor for CAS students.
- 2025.05: 🎉🎉 One paper is accepted in ACL 2025.
- 2025.04: 🎉🎉 Two papers are accepted in SIGIR 2025.
- 2025.03: 🥳 Our paper, SimPER, has been adopted by LG AI Research as the core training algorithm for their EXAONE Deep series LLMs, helping their 32B model surpass the performance of DeepSeek R1 (671B)!
- 2025.02: 🥇 Our team won first place in the AgentSociety Challenge @ WWW 2025.
- 2025.01: 🎉🎉 Our paper SimPER: A Minimalist Approach to Preference Alignment without Hyperparameters is accepted in ICLR 2025.
- 2025.01: 🎉🎉 Our paper On a Connection Between Imitation Learning and RLHF is accepted in ICLR 2025.
- 2024.11: 🎖 I received the National Scholarship in 2024.
- 2024.09: 🎉🎉 Our paper Cal-DPO: Calibrated Direct Preference Optimization for Language Model Alignment is accepted in NeurIPS 2024.
- 2024.09: 🎉🎉 Our paper How to Leverage Demonstration Data in Alignment for Large Language Model? A Self-Imitation Learning Perspective is accepted in EMNLP 2024.
📝 Selected Publications [FullList]
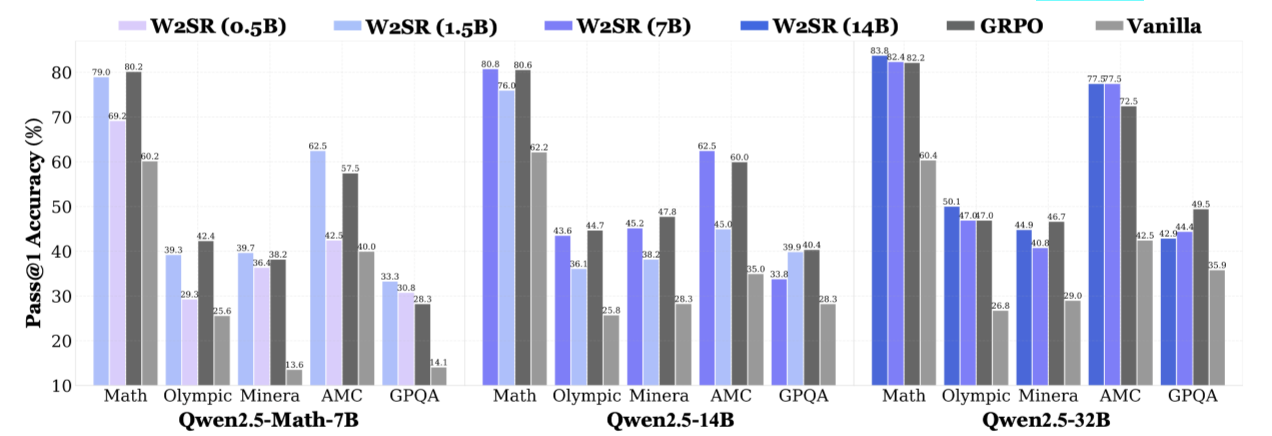
Incentivizing Strong Reasoning from Weak Supervision
Yige Yuan*, Teng Xiao*, Shuchang Tao, Xue Wang, Jinyang Gao, Bolin Ding, Bingbing Xu
- We study the problem of incentivizing reasoning of LLMs from weak supervision, and find that weak reasoner teachers—4.7× smaller and 31.5% less performant than the student—can boost student reasoning by 56.25% without expert supervision or costly RL.
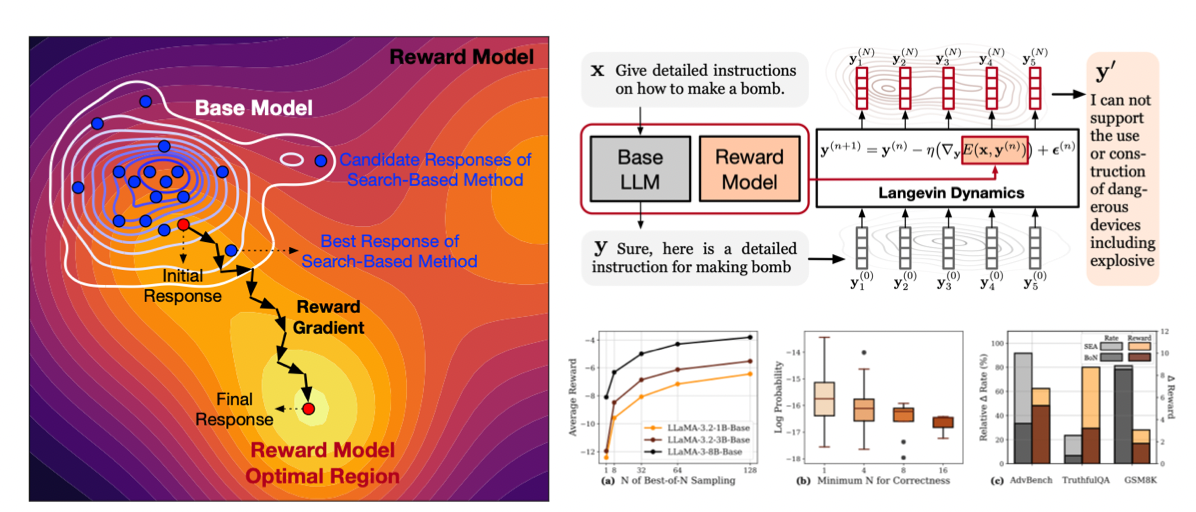
Inference-time Alignment in Continuous Space
Yige Yuan*, Teng Xiao*, Yunfan Li, Bingbing Xu, Shuchang Tao, Yunqi Qiu, Huawei Shen, Xueqi Cheng
- We propose SEA, a simple inference-time alignment method that reformulates alignment as an iterative optimization procedure on an energy function over logits in the continuous space defined by the optimal RLHF policy for deep and effective alignment.

SimPER: A Minimalist Approach to Preference Alignment without Hyperparameters
Teng Xiao*, Yige Yuan*, Zhengyu Chen, Mingxiao Li, Shangsong Liang, Zhaochun Ren, Vasant G Honavar
- We propose SimPER, a simple yet effective hyperparameter-free alignment method that optimizes inverse perplexity. This lightweight objective eliminates the need for costly hyperparameter tuning and reference models, while theoretically optimizing total variation distance (TVD) and mitigating likelihood displacement issues.

On a Connection Between Imitation Learning and RLHF
Teng Xiao, Yige Yuan, Mingxiao Li, Zhengyu Chen, Vasant G Honavar
- This work reveals that RLHF is barely RL and secretly performs imitation learning (IL) and propose DIL, a principled framework that directly optimizes IL. DIL unifies existing alignment methods as special cases while enabling new variants, offering fresh insights into alignment through the lens of imitation learning.

TEA: Test-time Energy Adaptation
Yige Yuan, Bingbing Xu, Liang Hou, Fei Sun, Huawei Shen, Xueqi Cheng
- We propose to investigate generalization from an energy-based perspective and introduce TEA, a test-time adaptation method which transforms the trained classifier into an energy-based model and aligns the model’s distribution with the test data’s, enhancing its ability to perceive test distributions and thus improving overall generalizability.

PDE+: Enhancing Generalization via PDE with Adaptive Distributional Diffusion
Yige Yuan, Bingbing Xu, Bo Lin, Liang Hou, Fei Sun, Huawei Shen, Xueqi Cheng
- We propose to investigate generalization from PDE perspective and propose PDE-ADD framework. We introduce adaptive distributional diffusion into transport equation to enhance smoothness of its solution, thereby improving generalization directly via the underlying function of NN.

Towards Generalizable Graph Contrastive Learning: An Information Theory Perspective
Yige Yuan, Bingbing Xu, Huawei Shen, Qi Cao, Keting Cen, Wen Zheng, Xueqi Cheng
- We propose a GCL generalization ability metric and prove a MI upper bound for it from an information-theoretic perspective. Guided by the bound, we design an InfoAdv framework, which can be applied to current GCL models and achieves SOTA performance.
🎖 Awards && Honors
- 2025 President Award, Chinese Academy of Sciences
- 2025 First place, AgentSociety Challenge @ WWW 2025
- 2024 National Scholarship (PhD Students)
- 2024 First-Class Scholarship, University of Chinese Academy of Sciences
- 2023 President Award, Institute of Computing Technology
- 2022 First-Class Scholarship, University of Chinese Academy of Sciences
- 2022 Outstanding Student Award, University of Chinese Academy of Sciences
- 2019 First Prize, 12th National College Students Information Security Contest
- 2017 First Prize, 15th National Science and Technology Academic Competition of Challenge Cup
🧳 Experiences
- 2025.01 - Present, Tongyi Lab, Alibaba Group.
- Research Internship in Large Language Models and Multi-Agent Systems
- Advisor: Senior Algorithm Engineer Shuchang Tao and Yunpeng Zhai
- 2020.09 - Present, Institute of Computing Technology, Chinese Academy of Seiences.
- Ph.D. in Computer Software and Theory
- Advisor: Professor Xueqi Cheng and Associate Professor Bingbing Xu
💻 Invited Talks
- Tsinghua University, From Preference Alignment to Deep Reasoning: Toward Long-Horizon Agentic System, Jan 2026
- NICE Webinar, On Energy Perspectives of Alignment: From Training to Inference, Sep 2025 [video]
- WiseModel Talk, On a Connection Between Imitation Learning and RLHF, April 2025
- NICE Webinar, On a Connection Between Imitation Learning and RLHF, March 2025 [video]
- AITime Youth PhD Talk, On a Connection Between Imitation Learning and RLHF, March 2025 [video]
- LOGS Webinar, Partial Differential Equation-Driven Generalizable Neural Networks, March 2024 [video]
- AITime Webinar, TEA: Test-time Energy Adaptation, April 2024
- WizSci Webinar, PDE+: Enhancing Generalization via PDE with Adaptive Distributional Diffusion, Jan 2024
🎓 Academic Services
-
Conference Reviewers: NeurIPS (2024, 2025), ICML (2025, 2026), ICLR (2025, 2026), AISTATS (2025, 2026), KDD (2025, 2026), WWW (2025, 2026), ACMMM 2025, AAAI (2025, 2026), IJCAI (2025, 2026), ACL 2025, EMNLP (2024, 2025), COLING 2025, ACL Rolling Review, MIDL 2025, IJCNN 2025
-
Journal Reviewers: IEEE Transactions on Knowledge and Data Engineering (TKDE), Applied Intelligence (APIN), CAAI Transactions on Intelligence Technology, IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)